
¿Cómo funciona el clustering en minería de datos?
Diseño web y UXEl machine learning se posiciona como una tecnología imprescindible para el futuro empresarial. Técnicas como el clustering permiten agrupar datos similares de manera no supervisada. Por tanto, se consigue ahorrar tiempo, aumentar la productividad y reducir los costes para las empresas.
Pero puesto que los mercados son cada vez más competitivos, es fundamental contar con una formación especializada que permita dominar estas herramientas. El Máster en Business Analytics e Inteligencia Artificial te da una preparación integral para enfrentar los retos actuales. Por ejemplo, almacenamiento, gestión e interpretación de datos.
¿Qué es el clustering?
El clustering es una técnica que forma parte del aprendizaje automatizado. Permite que los algoritmos entrenen con volúmenes de datos muy grandes de manera eficiente. Por tanto, se reducen los errores y se mejora la capacidad de análisis.
Su función principal es agrupar datos en clústeres. Es decir, en conjuntos de información con características similares. Esta técnica es especialmente útil en el Big Data, puesto que en este campo la gestión y segmentación de cantidades grandes de información son clave para las empresas.
El clustering se aplica en modelos analíticos de machine learning no supervisados. Es esencial para optimizar tareas y mejorar la toma de decisiones en entornos empresariales. Con ello, se permite lo siguiente:
- Analizar datos de manera automática.
- Detectar y corregir posibles errores.
- Segmentar información en grupos homogéneos para simplificar el procesamiento de los datos.

¿Cómo funciona un algoritmo de clustering?
El clustering es una técnica de minería de datos, o data mining, que tiene como objetivo principal formar grupos homogéneos y bien definidos a partir de un conjunto de elementos con características diversas, pero relacionadas entre sí. Para lograr esto, el algoritmo sigue un proceso estructurado que incluye la recopilación de datos, su análisis, la construcción de modelos y la generación de informes. A partir de estos, se pueden tomar decisiones basadas en la información obtenida.
La calidad de los datos es un factor determinante en el funcionamiento de los algoritmos de clustering. Para que los resultados sean fiables, es necesario que los datos sean precisos, completos y relevantes. Además, se debe definir de forma previa el número de grupos o clústeres que se desea obtener, ya que esto influye directamente en la efectividad del modelo.
Otro factor importante es el tamaño y las diferencias entre los clústeres. El algoritmo debe ser capaz de identificar y separar los datos en grupos que sean internamente coherentes, pero al mismo tiempo, distintos entre sí. Por último, también hay que tener en cuenta la forma en que se ordenan y presentan los clústeres, ya que facilita la interpretación de los resultados y su aplicación en las estrategias empresariales.
Clasificación de los algoritmos de clustering según su relación
Los algoritmos de clustering se encargan de agrupar objetos dentro de un dataset, en función de sus similitudes. De este modo, se pueden organizar y analizar volúmenes de datos grandes de manera eficiente. Dado que el clustering es una tarea de aprendizaje no supervisado, los algoritmos trabajan con datos no etiquetados, buscando patrones y relaciones por sí mismos para formar grupos coherentes.
Según la forma en que los objetos se relacionan entre sí y con los clústeres, los algoritmos de clustering se clasifican en dos categorías principales:
- Clustering rígido. Cada objeto pertenece exclusivamente a un único clúster. Es una metodología estricta donde no hay solapamientos ni grados de pertenencia.
- Clustering blando. Los objetos pueden pertenecer a varios clústeres, según su grado de confianza o probabilidad de pertenencia. Se trata de un enfoque más flexible y que refleja mejor la incertidumbre que hay en la asignación de grupos.
Aparte de esta, existe una clasificación más detallada que nos permite comprender cómo funcionan estos algoritmos. Es la siguiente:
- Partición estricta. Cada objeto se asigna a un único clúster, sin excepciones.
- Partición estricta con outliers. Es parecida a la anterior, pero permite que algunos objetos no pertenezcan a ningún clúster. Se les identifica como valores atípicos.
- Clustering con superposiciones. Los objetos pueden formar parte de más de un clúster de manera simultánea. Es útil en los casos en los que las fronteras entre grupos no están claramente definidas.
- Clustering jerárquico. Los clústeres se organizan en una estructura jerárquica, de modo que un objeto que pertenece a un clúster también forma parte de su clúster padre. Con esta característica, se crea una relación de subordinación entre los grupos.
Esta clasificación permite seleccionar el tipo de algoritmo más adecuado según las necesidades del análisis, ya sea para obtener agrupaciones estrictas, flexibles o jerárquicas.
Tipos de algoritmos de clustering más utilizados
Como hemos visto, los métodos de clustering forman parte de las técnicas de machine learning y, más concretamente, del aprendizaje no supervisado. Aunque existen múltiples métodos, dos de los más utilizados y conocidos son el K-means y el Clustering jerárquico.
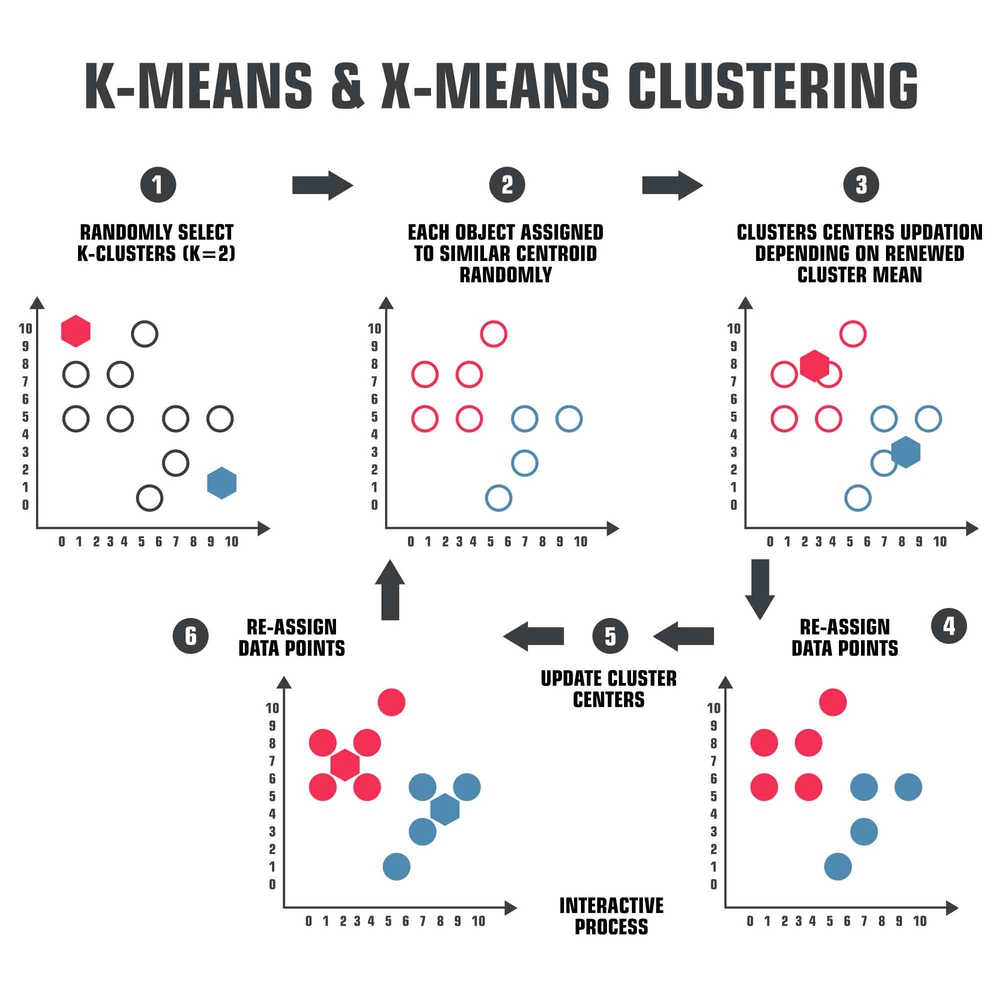
K-means
El K-means clustering es un método no jerárquico que se utiliza para agrupar objetos. Se divide el conjunto de datos en clústeres que no se solapan entre sí. Una característica importante de este método es que requiere definir de antemano el número de clústeres en los que se dividirán los datos.
Por esta razón, y para elegir el número adecuado de grupos, es necesario tener un conocimiento profundo del conjunto de los datos. Este método es eficaz cuando se busca una partición clara y definida de los datos.
Clustering jerárquico
Por su parte, el Clustering jerárquico ofrece una mayor flexibilidad, ya que no es necesario especificar el número de clústeres desde el inicio. Este método construye una estructura jerárquica que se representa mediante dendrogramas, los cuales muestran las relaciones entre los elementos de forma visual y ordenada.
Los dendrogramas son herramientas gráficas que ilustran la organización jerárquica de los datos, ya sea de forma horizontal o vertical. A partir de esta representación, se puede identificar la forma en que se agrupan los elementos y cómo se relacionan entre sí. Este sistema facilita la interpretación de los resultados y la toma de decisiones basada en la estructura de los datos.
Aunque cada método tiene su propio enfoque, ambos son fundamentales para el análisis de datos. Además, se adaptan a diferentes necesidades según la naturaleza del problema a resolver.
¿Cómo se utiliza el clustering en la minería de datos?
El clustering es una herramienta esencial en la minería de datos, puesto que permite descubrir patrones ocultos y estructuras dentro de volúmenes grandes de información. Su aplicación es especialmente útil en la segmentación de mercados. En ella, se agrupan clientes con comportamientos o características similares para diseñar estrategias personalizadas.
También se utiliza en la detección de anomalías, ya que identifica datos atípicos que podrían indicar fraudes, errores o comportamientos inusuales. Además, en el ámbito científico, el clustering ayuda a clasificar información biológica, como genes o proteínas, para facilitar avances en investigación médica y genómica.
Otra aplicación destacada del clustering IA es la organización y categorización de documentos o contenidos en el ámbito del procesamiento de lenguaje natural (NLP). Por ejemplo, en sistemas de recomendación, como los utilizados por plataformas de streaming o comercio electrónico, el clustering agrupa usuarios o productos con preferencias similares. A partir de ahí, se ofrecen sugerencias más precisas. Su versatilidad y capacidad para trabajar con datos no etiquetados lo convierten en una técnica indispensable para extraer valor de la información y apoyar la toma de decisiones en diversos sectores.
Si quieres aprender más sobre técnicas como esta para adaptarte a las necesidades actuales del mundo empresarial, solo tienes que inscribirte en nuestro máster.

